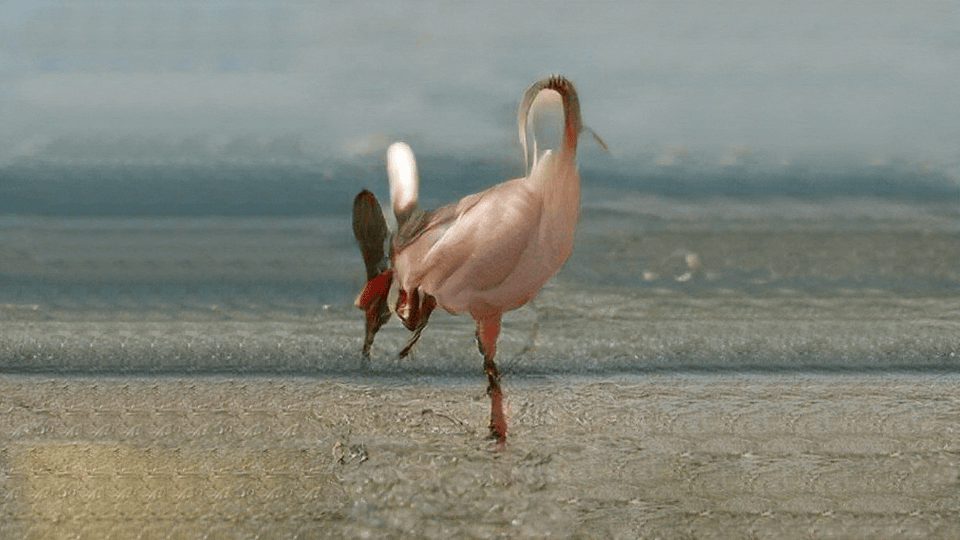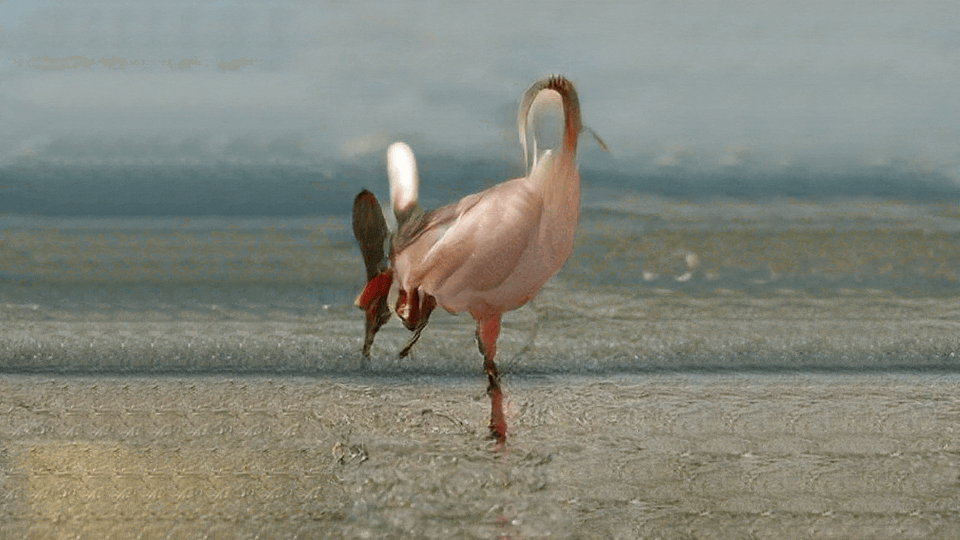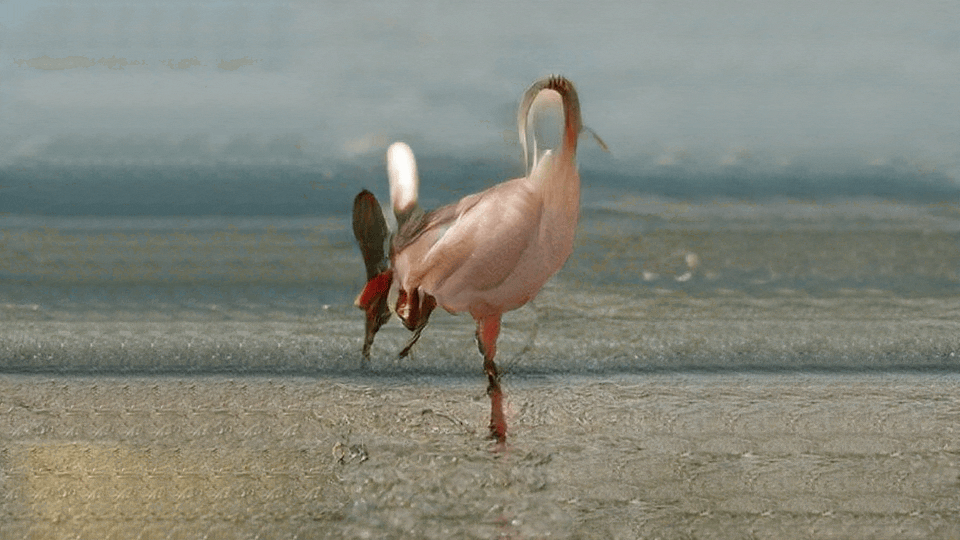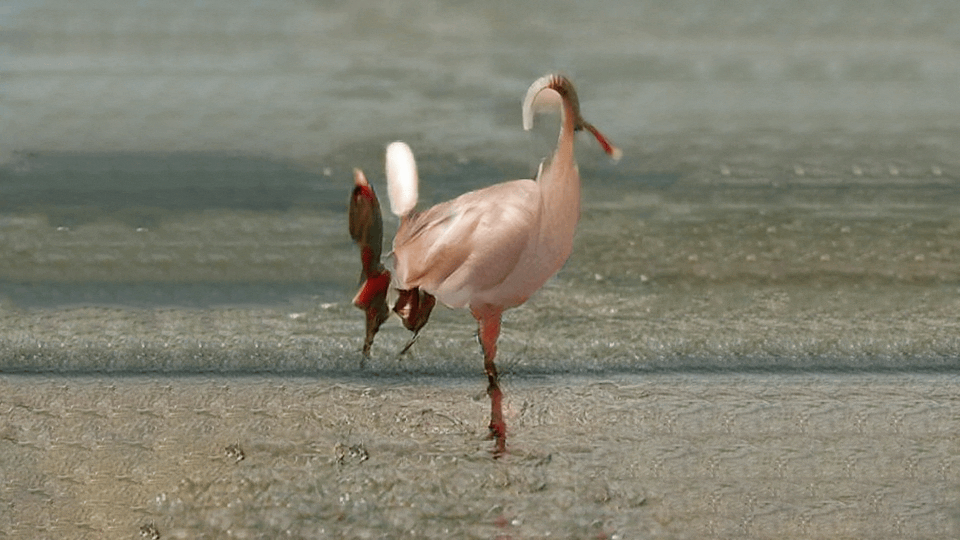
Il 23 ottobre 2018 nella sede newyorchese di Christie’s si tiene un’asta di 363 lotti che comprende, tra le altre, un’opera di Andy Warhol – aggiudicata per 75.000 dollari –, un’opera di Roy Lichtenstein – aggiudicata per 87.500 dollari – e un’opera del collettivo francese Obvious intitolata Edmond de Belamy, che partendo da una stima tra i 7.000 e 10.000 dollari viene aggiudicata a un compratore anonimo per 432.000 dollari.
La notizia fa il giro del mondo, non tanto per la cifra – i dipinti più costosi si aggirano sulle centinaia di milioni di dollari – ma perché Edmond de Belamy è un’opera creata grazie a un’intelligenza artificiale, più precisamente a un GAN, acronimo di Generative Adversarial Network.
Nel territorio dell’uncanny
L’opera è parte di una serie, La Famille de Belamy, il cui titolo ricalca in francese il cognome del ricercatore Ian Goodfellow: è lui, nel 2014, ad aver inventato l’algoritmo alla base del GAN. Ed è proprio una stringa dell’algoritmo, min G max D x [log (D(x))] + z [log(1 – D (G(z)))], che il collettivo Obvious appone come firma delle opere della serie.
È a questo punto che nel dibattito compare la figura di Robbie Barrat, artista e programmatore all’epoca diciannovenne, che ha scritto parte fondamentale del codice utilizzato dagli Obvious per la produzione della serie, poi messo a disposizione su GitHub.
Chi dobbiamo considerare come autore dell’opera? Il collettivo Obvious? L’intelligenza artificiale? Ian Goodfellow? Robbie Barrat? Un articolo di The Verge ne ricostruisce la vicenda.
Un GAN è composto da una AI che lavora per creare delle immagini, e da una seconda AI che analizza i risultati per determinare se le immagini siano vere o false.
Quella che può sembrare una polemica relativamente sterile su questioni di copyright nasconde una serie di domande complesse: un’intelligenza artificiale può essere considerata creativa? O al contrario, deve essere considerata come un’opera? O piuttosto come uno strumento?
Per farsi un’opinione bisogna prima comprendere a grandi linee il funzionamento di un Generative Adversarial Network. Un GAN è composto da un’intelligenza artificiale che lavora per creare delle immagini, e da una seconda intelligenza artificiale che analizza i risultati per determinare se le immagini siano vere o false. Con una metafora significativa, Goodfellow invita a immaginare un GAN «like an artist and an art critic. The generative model wants to fool the art critic – trick the art critic into thinking the images it generates are real».
Elemento preliminare perché questo possa accadere è l’operazione di deep learning: le intelligenze artificiali devono essere “nutrite” della maggiore quantità possibile di immagini da cui ricavare i parametri per il riconoscimento. L’efficacia del deep learning dipende però da diversi fattori, tra cui la quantità e la varietà di immagini che vengono sottoposte all’intelligenza artificiale – nel caso di La Famille de Belamy, per esempio, si tratta di 15.000 ritratti datati dal XIV al XIX secolo tratti da WikiArt. Gli artisti che usano i GAN considerano la cura e la personalizzazione dei database per il deep learning come uno dei momenti fondamentali del processo artistico, poiché sarà questa selezione a costituire l’universo visivo alla base della generazione delle opere.

L’idea di un sistema di riconoscimento e generazione di immagini nasce con l’obiettivo di identificare e creare immagini realistiche o quantomeno ascrivibili a un universo visivo noto, come ad esempio lo stile di un pittore. L’avvento di database sconfinati e di macchine estremamente potenti ha permesso, nel giro di pochi anni dall’invenzione del GAN, di raggiungere deepfake stupefacenti. Come spesso accade all’emergere di una nuova tecnologia, diversi artisti hanno sfruttato il mezzo in chiave critica, come il video di Gillian Wearing che tramite la creazione di deepfake di se stessa esplora i temi dell’identità, della tensione tra vita pubblica e privata e della differenza tra documentazione e costruzione del punto di vista.
Cercando “GAN art” su Google Immagini, però, non compaiono deepfake, ma immagini caratterizzate da un’estetica riconoscibile e tutt’altro che realistica. Osservando le opere di artisti come il già citato Barrat o il più noto Mario Klingemann, ci troviamo davanti a quello che lo stesso Klingemann definisce «Francis Bacon effect»: un effetto di distorsione dei volti e dei corpi umani inquietante, che ricorda appunto i dipinti di Bacon. Siamo nel territorio dell’uncanny.
Il concetto di uncanny viene esplorato da Sigmund Freud nell’opera Das Unheimliche e si potrebbe definire come l’inquietudine che sorge davanti a qualcosa di “stranamente familiare” – come una bambola o un manichino. Questo concetto viene poi ripreso negli anni Settanta dall’esperto di robotica Masahiro Mori che ipotizza la cosiddetta “uncanny valley”: una teoria secondo la quale l’esperienza psicologica dell’uncanny si attiva quando diventa difficile distinguere un automa o un robot da un essere umano in carne e ossa. Come evidenziato dalla biennale di Vienna del 2019, intitolata Uncanny Values: Artificial Intelligence & You, nel caso delle immagini prodotte dalle intelligenze artificiali il livello di inquietudine è doppio – provocato sia dal “Francis Bacon effect”, sia dalla consapevolezza di stare osservando un’opera creata da una macchina un po’ troppo somigliante a noi.
L’asimmetria del rapporto uomo-macchina
L’effetto perturbante si perde parzialmente – e anzi lascia il posto a un sentimento di meraviglia incantata – in lavori come quello di Sofia Crespo. Il suo lavoro non si concentra infatti sull’antropomorfismo, ma sfrutta i GAN per creare nuove immaginifiche possibilità biologiche, specie animali e vegetali artificiali piene di fascino.

Ma come emerge l’estetica della GAN art, caratterizzata da distorsioni come il “Francis Bacon effect”? Per rispondere a questa domanda dobbiamo fare un passo indietro, al 2015, quando Google – in seguito ai risultati altalenanti dei primi esperimenti sui GAN – si rende conto della potenza di quest’estetica surreale, allo stesso tempo inquietante e onirica, e decide di creare Deep Dream Generator, un software open source di generazione di immagini “imperfette” per permettere a tutti di sfruttare le possibilità creative del mezzo.
Le immagini di Deep Dream sono impressionanti perché sembrano quasi alludere all’esistenza di un subconscio della macchina – basti pensare a uno degli “errori” di interpretazione caratteristici di Deep Dream, la pareidolia, ossia la tendenza della corteccia cerebrale a riportare a forme note immagini o oggetti sconosciuti.
Ognuno di questi “errori”, una volta individuato, può essere corretto o esasperato. Ma c’è una complicazione: non è possibile osservare i processi interni dell’intelligenza artificiale al lavoro, ma solo i suoi output. È quindi solo attraverso lo studio delle immagini generate e continue modifiche al codice che è possibile personalizzare e direzionare i risultati. È proprio a partire dal processo di apprendimento dei GAN e dei loro malintesi interpretativi che gli artisti hanno cominciato a sperimentare.
Gli artisti che usano i GAN considerano la cura e la personalizzazione dei database per il deep learning come uno dei momenti fondamentali del processo artistico, poiché sarà questa selezione a costituire l’universo visivo alla base della generazione delle opere.
Questo deficit dei GAN non viene sfruttato dagli artisti solo come strumento per la creazione delle proprie opere, ma anche come soggetto delle opere stesse.
The City of Broken Windows di Hito Steyerl è un progetto incentrato sul tentativo di ricostruzione del suono di una finestra rotta da parte di un’intelligenza artificiale. Jules Laplace, il compositore e programmatore cha ha lavorato sul codice, racconta le difficoltà incontrate nella realizzazione dell’opera: come comprendere i parametri di classificazione del suono all’interno del GAN? Come scardinare le “scorciatoie cognitive” di un’intelligenza artificiale educata al riconoscimento di pattern per restituire invece la casualità di un rumore, come quello di una finestra rotta? I risultati di questo lavoro fanno da colonna sonora a un’installazione che affronta la cosiddetta Broken Windows Theory, secondo cui segni visibili di vandalismo e criminalità – come le finestre rotte – incoraggerebbero l’emulazione di questi gesti, dando così vita a un circolo vizioso. La Broken Windows Theory è stata recentemente assimilata in controversi sistemi predittivi basati sull’intelligenza artificiale con l’obiettivo di individuare quartieri o gruppi sociali considerati ad alto rischio di comportamento criminale. Una teoria fondata sul pregiudizio viene quindi data in pasto a un sistema tecnologico di cui non possiamo individuare i criteri. L’opera di Steyerl ci mette in guardia da quella che Zach Blas ha definito «una psichedelia neoliberista, dove le più grandi allucinazioni del presente vengono generate da algoritmi paranoici che vogliono vedere cani e volti di terroristi dappertutto».

Sui rischi connessi all’utilizzo dei GAN si concentra anche Trevor Paglen, la cui pratica artistica è incentrata sull’analisi e la critica dei sistemi di sorveglianza e raccolta dati. Recentemente, si è occupato del processo visivo dei GAN: «Something dramatic has happened to the world of images: they have become detached from human eyes. Our machines have learned to see [w]ithout us… I call this world of machine-[to]-machine image-making ‘invisible images’, because it’s a form of vision that’s inherently inaccessible to human eyes».
I suoi progetti Study for Invisible Images e From Apple to Anomaly analizzano i database di immagini utilizzati per educare le intelligenze artificiali: la sua opera pone l’attenzione su come la visione macchina-macchina influenzi la nostra percezione delle immagini e della realtà stessa.
L’installazione From Apple to Anomaly si apre con Ceci n’est pas une pomme, un’opera di Magritte che diventa per Paglen l’occasione per riflettere sulla differenza tra visione umana e artificiale, e sulle sue implicazioni concettuali e politiche: «In the case of the Magritte painting, it’s a picture of an apple – that says ‘this is not an apple’. And for me, that becomes a kind of allegory for a kind of self-representation – an acknowledgement that representations are always relational and they are based on some kind of consensus. And those consensuses can change. We think about a lot of queer or feminist liberation projects are about trying to change the meaning of images – to be able to define the meaning of one’s own image. In Magritte’s painting, it’s pointing in that direction, to the politics of representation. And then to have the computer vision system imposing its will on that image and saying, ‘No I don’t care what you think you’re doing here, Magritte, this is a picture of an apple’».
Tornando alla questione dell’autorialità, va notato come il collettivo Obvious usi furbescamente la stringa del codice di Goodfellow come firma delle opere, ma nel proprio manifesto artistico tenga a sottolineare come l’intelligenza artificiale sia da considerarsi nient’altro che uno strumento di una pratica artistica umana. Al di là della contraddizione degli Obvious, questa è la posizione maggioritaria tra gli artisti: i GAN sono uno strumento o tuttalpiù una protesi che permette da una parte di espandere la propria pratica artistica, dall’altra di innescare nuovi meccanismi visivi, i cui limiti e virtù sono in questi anni soggetto di indagine e ispirazione – il fronte transumanista è ancora una minoranza.
A offrire un punto di vista alternativo è Pierre Huyghe con UUmwelt. Huyghe ha chiesto ad alcuni volontari di pensare intensamente a delle immagini mentre venivano sottoposti a una risonanza magnetica. I risultati della risonanza sono stati poi trasferiti a un software di intelligenza artificiale programmato per decodificare l’attività cerebrale in forma di immagine. Le figure prodotte, ancora una volta, riportano all’uncanny. L’obiettivo di Pierre Huyghe è però un altro: porre l’attenzione sull’asimmetria del rapporto uomo-macchina. Un’asimmetria che l’artista decide di ribaltare: le immagini non sono opere create da una macchina per venire contemplate dagli esseri umani ma, anzi, documentano precisamente l’opposto: «Non voglio mostrare qualcosa a qualcuno, ma il contrario: voglio mostrare qualcuno a qualcosa».






